Export defines a set of dataset properties, which will be exported to a spreadsheet file along with the values of respective indicators. Each export must be referenced from it's parent view.
Export counts in all active filters and the map selection.
Syntax
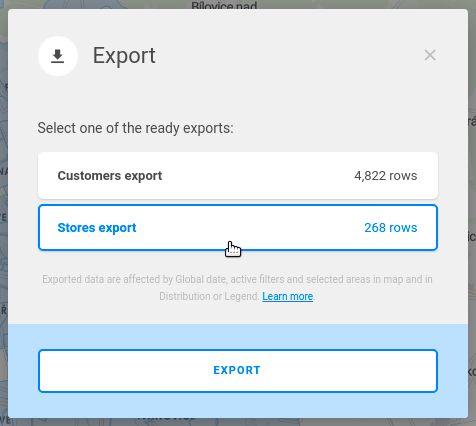
This is one of the exports from the Retail Solution Demo. As you can see, a good description is important.
Export object syntax
{
"name": "customer_ids_export",
"type": "export",
"title": "List of Customer IDs",
"description": "Returns client IDs, Districts, Wards and indicators available in the view into CSV file.",
"content": {
"properties": [
"baskets.client_id",
"district.districtname",
"ward.wardname"
]
}
}
Example of a dumped export
{
"url": "/rest/projects/yufqzxkbiecj7jot/md/exports/g3v603i8m3tre30g",
"dumpTime": "2018-01-30T13:48:17Z",
"version": "8",
"content": {
"id": "g3v603i8m3tre30g",
"name": "customer_ids_export",
"type": "export",
"title": "List of Customer IDs",
"description": "Returns client IDs, Districts, Wards and indicators available in the view into CSV file.",
"content": {
"properties": [
"baskets.client_id",
"district.districtname",
"ward.wardname"
]
},
"accessInfo": {
"createdAt": "2017-11-13T14:12:57Z",
"modifiedAt": "2018-01-30T12:48:18Z"
},
"links": [
{
"rel": "self",
"href": "/rest/projects/yufqzxkbiecj7jot/md/exports/g3v603i8m3tre30g"
}
]
}
}
Additional syntax examples
Export allows to set default output settings - output filename, file type, file format and header format.
Export with output object
{
"name": "transaction_ids_export",
"type": "export",
"title": "List of Transaction IDs",
"description": "Returns transactions ID, postcodes, lower super output areas, middle super output areas and value of indicators available in the view into a file.",
"content": {
"properties": [
"codepoint_plg.msoa11nm",
"codepoint_plg.lsoa11nm",
"codepoint_plg.postcode",
"baskets.basket_id"
],
"output": {
"type": "file",
"format": "xlsx",
"filename": "Transaction IDs.xlsx"
"header": "basic"
}
}
}
Key description
content
|
Key |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
array |
required |
array of dataset properties, which will be present in the exported file |
|
|
|
object |
optional |
export output settings |
|
content.output
|
Key |
Type |
Optionality |
Description |
Constraints |
|---|---|---|---|---|
|
|
string |
required |
output type (at the moment, only |
|
|
|
string |
required |
file format |
|
|
|
string |
optional |
custom filename |
|
|
|
string |
optional |
header format |
|
Visual representation
All project exports can be viewed in the export dialogue. This dialogue can be accessible by clicking the Menu button in the top left corner ( ![]()
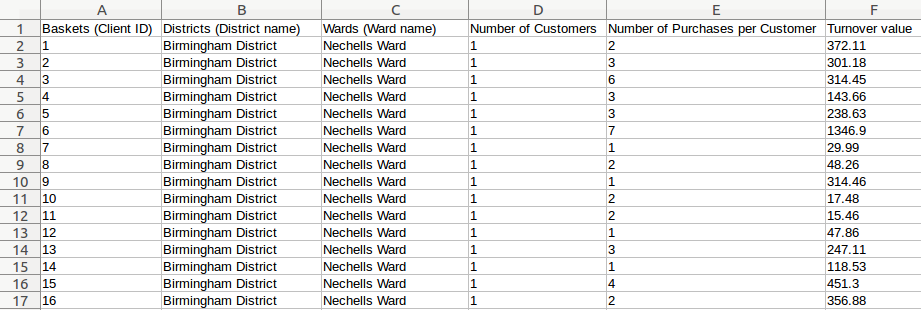
Exported file in a spreadsheet editor
Preventing duplicate records
It is a good practice to also include the primary key in the export definition, otherwise it can lead to duplicate records in the result of the export process. The duplicate records can occur because the dataset's columns and metric values need to be joined and if there is no primary key, then the join is performed using all available columns. And if any of the columns contains some NULL values, the join process is not able to correctly match the records, because of the NULL values inequality.
Let's give an example. We have a dataset of branches like this:
|
branch_id |
branch_name |
city |
|---|---|---|
|
10 |
Branch Prague |
Prague |
|
20 |
Branch London |
London |
|
30 |
Branch New York |
NULL |
The correct definition of the export would look like this:
"content": {
"properties": [
"branches.branch_id",
"branches.branch_name",
"branches.city"
]
}
In this case the metric values are correctly joined based on the primary key branches.branch_id. The result would look like this:
|
branch_id |
branch_name |
city |
number_of_employees |
|---|---|---|---|
|
10 |
Branch Prague |
Prague |
100 |
|
20 |
Branch London |
London |
250 |
|
30 |
Branch New York |
NULL |
300 |
The incorrect definition of the export would look like this:
"content": {
"properties": [
"branches.branch_name",
"branches.city"
]
}
In this case, the metric values need to be joined using columns branches.branch_name and branches.branch_city, because there is no primary key defined. And because the column city contains NULL value on the third row, the records are not correctly matched in the case of "Branch New York" and it results to duplicate records.
The result would look like this:
|
branch_id |
branch_name |
city |
number_of_employees |
|---|---|---|---|
|
10 |
Branch Prague |
Prague |
100 |
|
20 |
Branch London |
London |
250 |
|
30 |
Branch New York |
NULL |
NULL |
|
NULL |
NULL |
NULL |
300 |